
Digital Collections

Contents
Overview

A lot of my work has been to provide infrastructure for digital library collections. I manage a digital repository, make websites, provide search interfaces for cultural heritage materials, and I look for ways to build searches that let people explore in satisfying ways.
Digitized items from the Goodspeed Manuscript Collection, by century
Managing digital collections projects
These cultural heritage materials inclue things like notes, letters, engravings, photographs, manuscripts, sound recordings, videos, and more. The first step in getting these materials online is to run a digitization project to create digital surrogates of these items. These projects need to be managed—they need accurate inventories to be sure that every physical item is accounted for and to manage the digitization process. They also need specifications for things like resolution and bit depth of the resulting files, file naming schemes and a specification for how files should be laid out on disk, as well as standards for image, sound, or video quality. Parallel to digitization, metadata specialists collect and enhance metadata to describe each digital object. Some type of identifier scheme needs to connect files on disk with specific metadata records. I have worked on teams to manage these projects either in-house or with external vendors, and I have also provided consulting and advice for teams taking on these projects elsewhere.
Quality control
Every digitization project I have worked on has also required some type of quality control and rework process, to make sure that all standards have been met, that files have been named and arranged accurately, and that metadata for all digital objects is complete. It is easy for this rework process to take longer than expected. I’ll use scripts to find inconsistencies in digital objects and metadata files, and I’ll work with vendors, digitization staff, and metadata specialists to correct problems. I also maintain programs to automatically correct filenaming errors, to modify files by doing things like automatically cropping images and deskewing them. I validate that files and metadata are well formed, and that metadata matches the expectations of all stakeholders. This can involve working with metadata in a variety of formats including MARC, MARCXML, various types of XML documents including TEI, DC, VRACore and more, relational databases or linked data.
Website development

In my experience these projects almost always involve displaying the newly digitized objects on some type of website—so it is important that there is a specification for this interface that can inform metadata and digitization work. We need to be sure that project metadata not only supports long term preservation and discovery of items, but that it can populate an interface for this project’s specific stakeholders and use cases. I often write reports and test assumptions about metadata to be sure it does what the website development team needs it to do.
Digital archiving
In our setup, digital object data are loaded into a digital repository which feeds into our image server and linked data triplestore for metadata. This ensures that whatever digital objects and metadata users see on a website is also being archived in the digital repository. I mint permanent identifiers for each digital object, which tie together the object’s working identifier, its files in the digital repository, and its metadata. Because these identifiers are permanent, we track them and put policies in place to provide access to them for the long term.
Serving images

The image server and manifest server pull image and metadata together into a standard form that can be used for website display. Currently we use IIIF Image Servers, IIIF Manifests, and EDM linked data to do this. Using standards like these allows our data to not only be used for the specific collection we’re working with, but it also puts it into interoperable formats that allow digital objects to be combined with others from other institutions, to be browsed and searched as a whole, and more.
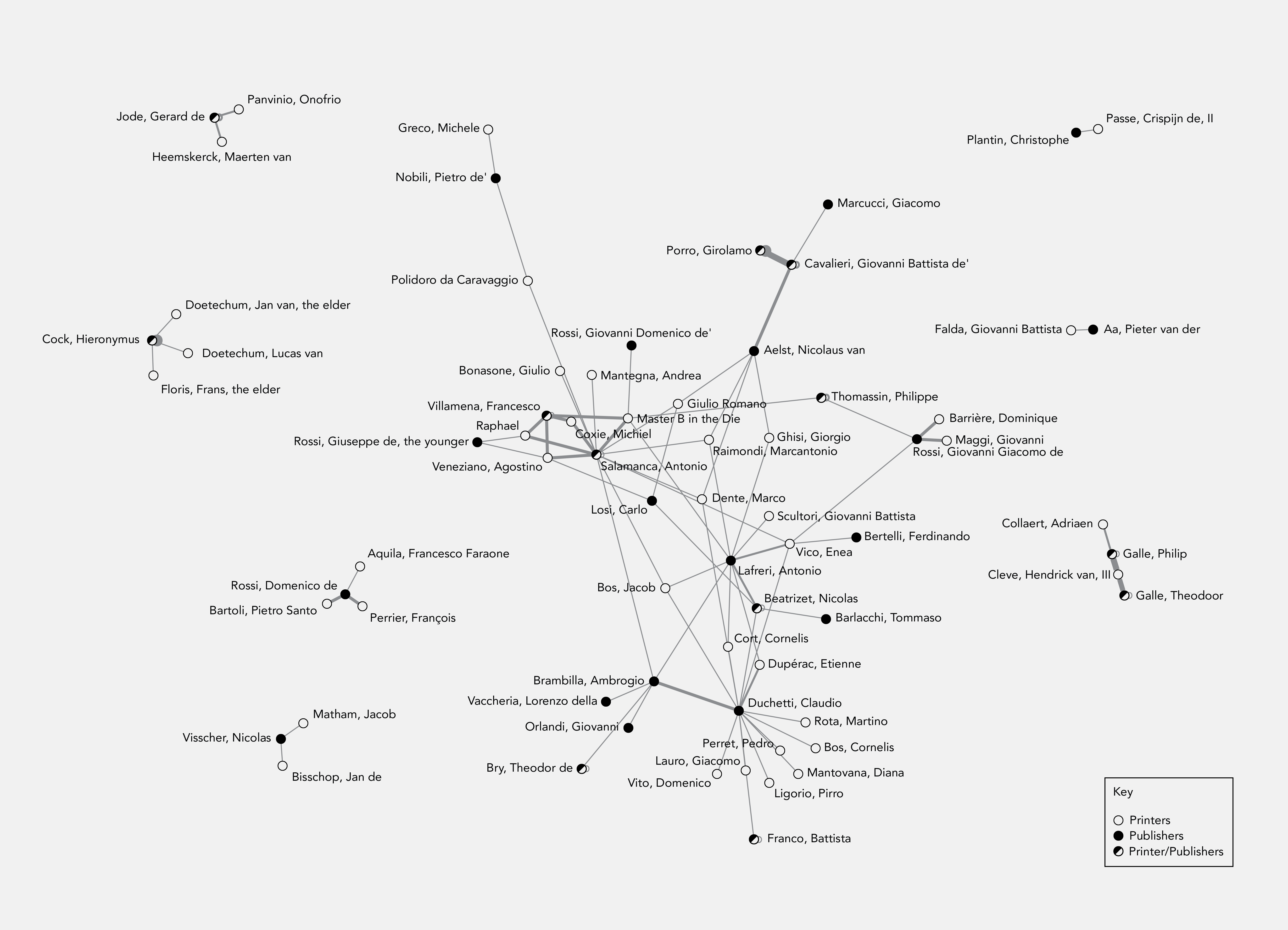
Artifacts
I have worked on digital collections projects for a few years. The first thumbnail below is for the current digital collections template at my place of work, and all thumbnails after that are for legacy projects. For the current template I worked as part of a team including a designer and two other developers, while for legacy projects I did both design and development work on my own.

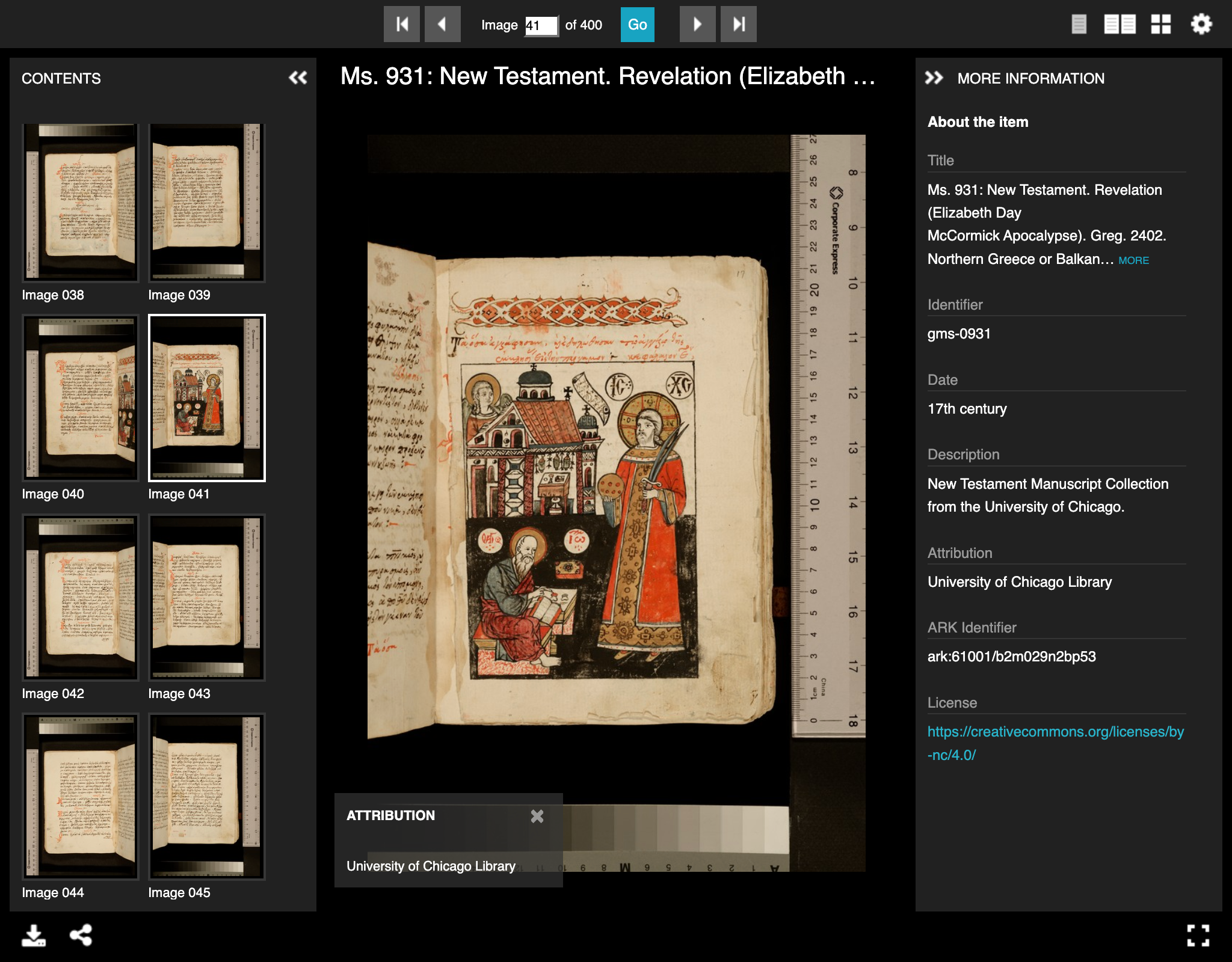
Automatic image cropping

This is an example of one of the image processing scripts I have written to manage images produced in a digitization project. When images are initially captured, scans or photographs often include a ruler or color bar that may be cropped out when the image is viewed on a website. Because it would be labor-intensive for a person to open hundreds or thousands of images in an image editor to manually crop these extraneous elements out, I wrote this script to automatically detect the position of a color bar in an image so that it could be cropped automatically.