
Campus Publications

Contents
Project overview

This project provides access to serial publications documenting the history of the University of Chicago and the work of its faculty, staff, students, and alumni. It includes publications produced by both administrative units and and student organizations on campus. There are two aspects of this site that I’m especially happy with. First, the site uses an older content management system to provide search and display for digital objects. The indexing, querying, and searching features continue to meet the site requirements completely. However, the system includes a way to upload HTML templates to provide custom frontends, and it does that in a way that is non-standard when compared to current web development practice.
Because of that I configured the system to work as an API. It accepts queries and rather than returning HTML pages for display in a web browser, instead it returns data that can be processed and displayed in whatever system you’d like.
I also wrote a suite of tools to validate data to be ingested into the system, fix problems, and transform data into the two different formats we need for this project—one for our long term digital archive, and the other for the website display.
This project is ongoing. Currently there are 10 titles, 454 volumes, 9,533 issues, and 145,529 searchable pages in the system.
Using a custom web framework With XTF
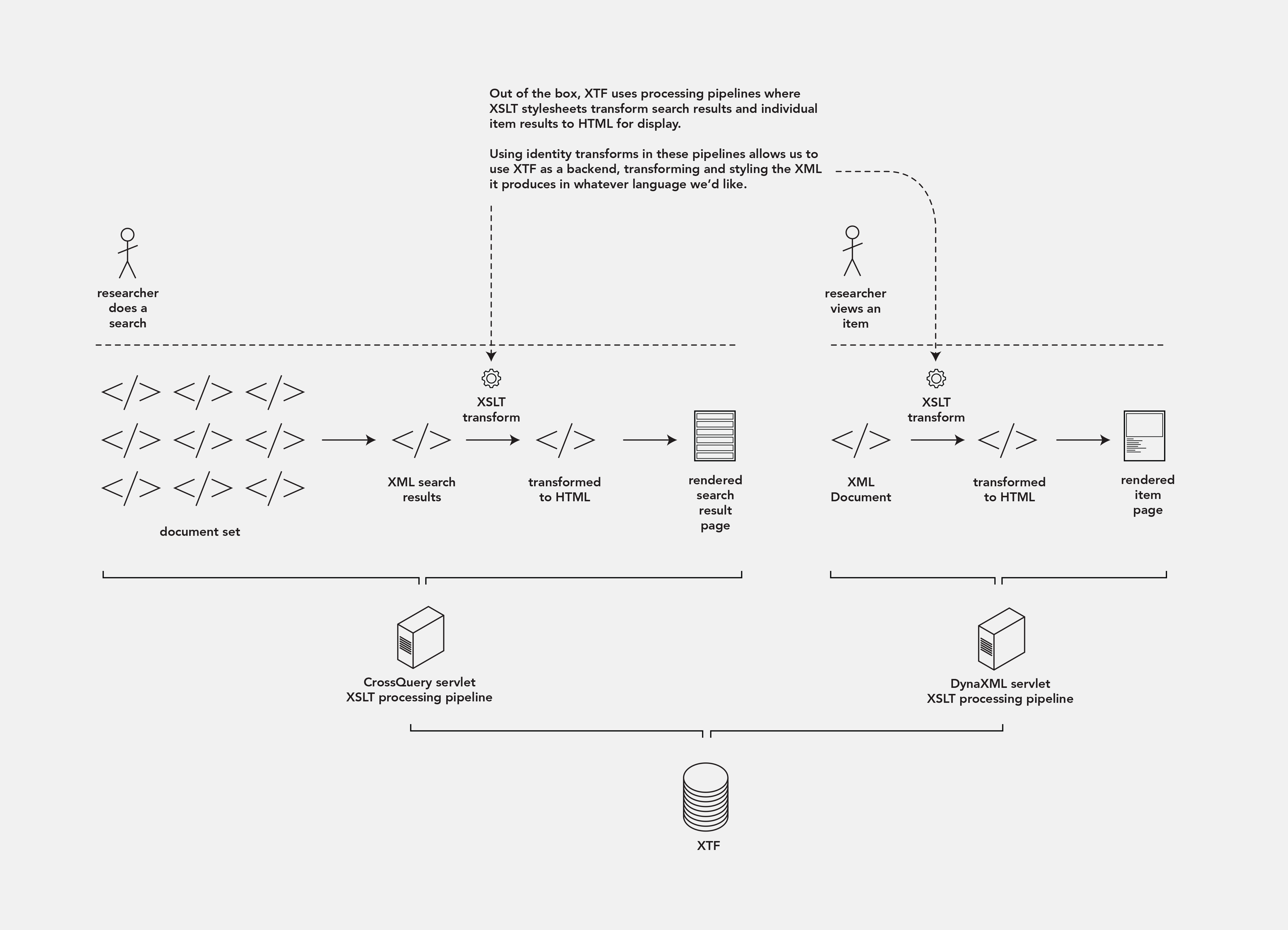
XTF is composed of two basic parts—a search engine that includes the ability to index different types of content, and return page images with the coordinates of search results highlighted, and a system for customizing the design of web pages for different searches, browses, and views. The system is customized using the eXtensible Stylesheet Language (XSLT), which is non-standard for modern web development and has a bit of a learning curve. Also, in spite of the fact that I feel pretty comfortable coding in XSLT, I code much faster in other languages.) Because of that we use the backend features of XTF only. This way we can attach it to any kind of frontend we’d like. The Campus Publications site currently uses a minimal PHP website as its frontend, although at least one other installation who borrowed this pattern used a Django-based front end.
Software for this project
Most digital collections require some kind of backend tooling to be able to manage files and data. Here is an overview of the tools I produced for this project.
Validation tools
I mantain a set of scripts to validate that data has been exported correctly, that filenames match the pattern we need them to, that all of the data for a particular issue is complete and that it is stored in the correct hierarchy in the filesystem. This is all necessary because we’ll need to load these files into different systems, each with their own requirements for file formats, naming, and organization. Making sure that the files conform to an initial specification is important. Additionally, when it is being performed by humans, this kind of work is error prone. Because of that scripts are helpful to automatically identify problems.
Repair tools
Other scripts rebuild OCR, produce JPEG files or PDFs, rename files, and more. I wrote repair tools to be able to address common problems with files that can be addressed automatically.
Transformation tools
Once data has been quality controlled, validated and repaired, we can transform it to other formats. I maintain scripts to convert files to the Oxford Common File Layout (OCFL) for out library repository, and others convert files to the format required by the eXtensible Text Framework (XTF) from the California Digital Library. In the case of the XTF transformation we go from one of two OCR formats produced by our vendors to a third, required by XTF.
